Introducing File I/O for Kernel Browsers

Today we’re launching an API to read / write to the file system on Kernel’s hosted browsers. This is useful for a number of operations, but it’s especially useful for accessing files downloaded from Kernel browsers, such as receipts, invoices, CSVs, or any other document that a workflow automation might download from a website. With Kernel, AI agents can now access and manage documents downloaded from browsers the same way humans do on our personal computers.
Get started: docs
See source: Github
Why we built this
Kernel provides browsers-as-a-service for automations and AI agents that need to access websites without APIs—think government portals, healthcare systems, or software dashboards. In these cases, workflows often require downloading invoices, exporting reports, or saving documents.
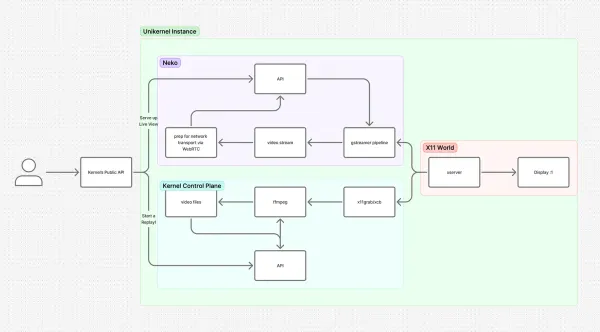
Most browser-as-a-service providers only make files available once the session has ended, which prevents real-time processing. We took a different approach: Kernel exposes the VM’s filesystem during the session. Agents can read, write, and organize files as soon as they’re created, enabling document processing, analysis, or storage while the browser is still active.
API overview
- Download and access files: Retrieve any file downloaded during a browser session, from simple documents to large datasets, with streaming support for memory-efficient processing.
- Manage the filesystem: Create, delete, move, and organize files and directories, with bulk operations like ZIP downloads and multi-file uploads.
- Monitor in real-time: Watch directories for changes, stream filesystem events, and access browser logs as they happen via Server-Sent Events.
- Seamless browser automation workflows: Download files through Playwright or Puppeteer and immediately access them via our API. Everything downloaded during the browser session is available until you need it.
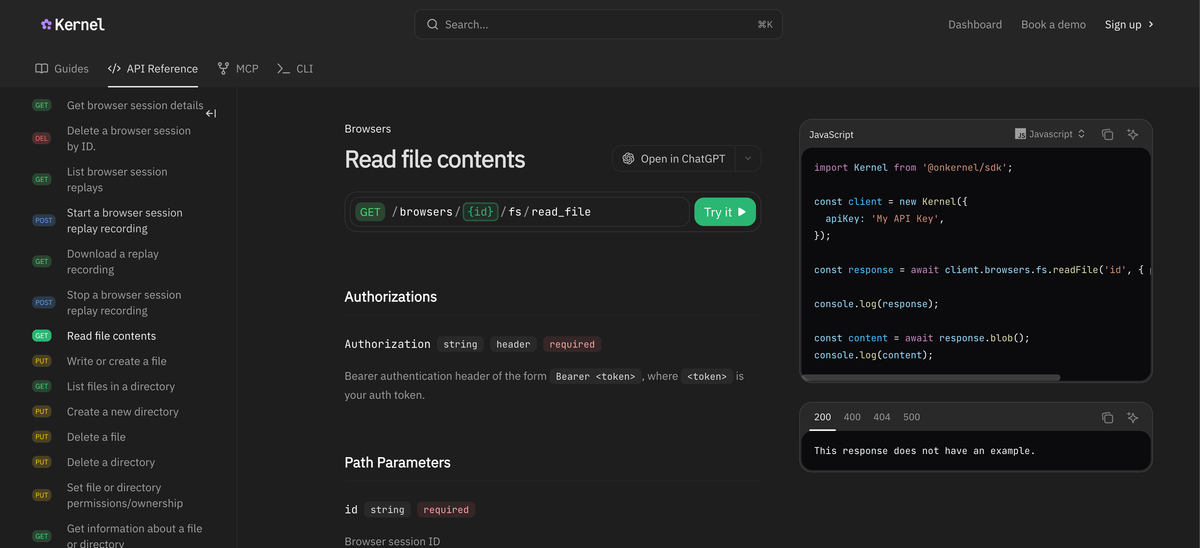
kernel.browsers.fs.readFile()
The simplest API call is to read a file from a running Kernel browser session: (see our docs for a full example):
const file = await kernel.browsers.fs.readFile('session_id', {
path: '/downloads/example.csv',
});
const content = await file.blob();Examples
Here’s how you can integrate file I/O into an automation workflow with Kernel:
- Launch a browser with Kernel
- Navigate to a website that requires file uploads or downloads, such as an insurance payer portal, ecommerce store, or ticketing website
- Upload or download files from the website using a browser automation framework (e.g. Playwright, Puppeteer)
- Send downloaded files via Kernel’s API to a S3 bucket for further storage and processing
Playwright (Typescript)
import { Kernel } from "@onkernel/sdk";
import fs from "fs";
import pTimeout from "p-timeout";
import { chromium } from "playwright";
const DOWNLOAD_DIR = "/tmp/downloads";
const kernel = new Kernel();
async function main() {
const kernelBrowser = await kernel.browsers.create();
console.log("live view:", kernelBrowser.browser_live_view_url);
const browser = await chromium.connectOverCDP(kernelBrowser.cdp_ws_url);
const context = (await browser.contexts()[0]) || (await browser.newContext());
const page = (await context.pages()[0]) || (await context.newPage());
// Required to prevent Playwright from overriding the location of the downloaded file
const client = await context.newCDPSession(page);
await client.send("Browser.setDownloadBehavior", {
behavior: "allow",
downloadPath: DOWNLOAD_DIR,
eventsEnabled: true,
});
// Set up CDP listeners to capture download filename and completion
let downloadFilename: string | undefined;
let downloadCompletedResolve!: () => void;
const downloadCompleted = new Promise<void>((resolve) => {
downloadCompletedResolve = resolve;
});
client.on("Browser.downloadWillBegin", (event) => {
downloadFilename = event.suggestedFilename ?? "unknown";
console.log("Download started:", downloadFilename);
});
client.on("Browser.downloadProgress", (event) => {
if (event.state === "completed" || event.state === "canceled") {
downloadCompletedResolve();
}
});
// Trigger the download in the page
console.log("Navigating to download test page");
await page.goto("https://browser-tests-alpha.vercel.app/api/download-test");
await page.getByRole("link", { name: "Download File" }).click();
try {
await pTimeout(downloadCompleted, {
milliseconds: 10_000,
message: new Error("Download timed out after 10 seconds"),
});
console.log("Download completed");
} catch (err) {
console.error(err);
throw err;
}
if (!downloadFilename) {
throw new Error("Unable to determine download filename");
}
// Download the file directly from the browser instance
const remotePath = `${DOWNLOAD_DIR}/${downloadFilename}`;
console.log(`Reading file: ${remotePath}`);
const resp = await kernel.browsers.fs.readFile(kernelBrowser.session_id, {
path: remotePath,
});
const bytes = await resp.bytes();
fs.mkdirSync("downloads", { recursive: true });
const localPath = `downloads/${downloadFilename}`;
fs.writeFileSync(localPath, bytes);
console.log(`Saved to ${localPath}`);
// Alternatively, stream directly to disk:
// import { pipeline } from 'node:stream/promises';
// import { createWriteStream } from 'node:fs';
// import { Readable } from 'node:stream';
// await pipeline(Readable.fromWeb(resp.body!), createWriteStream(localPath));
await browser.close();
}
main();Playwright (Python)
import asyncio
import os
from kernel import AsyncKernel
from playwright.async_api import async_playwright
DOWNLOAD_DIR = "/tmp/downloads"
client = AsyncKernel()
async def main():
# Create a new browser via Kernel
kbrowser = await client.browsers.create()
print("Kernel browser live view url:", kbrowser.browser_live_view_url)
async with async_playwright() as playwright:
browser = await playwright.chromium.connect_over_cdp(kbrowser.cdp_ws_url)
context = browser.contexts[0]
page = context.pages[0] if len(context.pages) > 0 else await context.new_page()
# Required to prevent Playwright from overriding the location of the downloaded file
cdp_session = await context.new_cdp_session(page)
await cdp_session.send(
"Browser.setDownloadBehavior",
{
"behavior": "allow",
"downloadPath": DOWNLOAD_DIR,
"eventsEnabled": True,
},
)
# Set up CDP listeners to capture download filename and completion
download_completed = asyncio.Event()
download_filename: str | None = None
def _on_download_begin(event):
nonlocal download_filename
download_filename = event.get("suggestedFilename", "unknown")
print(f"Download started: {download_filename}")
def _on_download_progress(event):
if event.get("state") in ["completed", "canceled"]:
download_completed.set()
cdp_session.on("Browser.downloadWillBegin", _on_download_begin)
cdp_session.on("Browser.downloadProgress", _on_download_progress)
# Trigger the download in the page
print("Navigating to download test page")
await page.goto("https://browser-tests-alpha.vercel.app/api/download-test")
await page.get_by_role("link", name="Download File").click()
try:
await asyncio.wait_for(download_completed.wait(), timeout=10)
print("Download completed")
except asyncio.TimeoutError:
print("Download timed out after 10 seconds")
# Download the file directly from the browser instance
resp = await client.browsers.fs.read_file(
kbrowser.session_id, path=f"{DOWNLOAD_DIR}/{download_filename}"
)
local_path = f"./downloads/{download_filename}"
os.makedirs("./downloads", exist_ok=True)
await resp.write_to_file(local_path) # streaming; file never in memory
print(f"Saved to {local_path}")
await browser.close()
if __name__ == "__main__":
asyncio.run(main())Security
Each browser runs in its own sandboxed unikernel, so filesystem access is confined to that VM. This design lets automations fully interact with the environment securely while making document-heavy workflows much easier to build at scale.
These APIs—and the rest of the infrastructure powering our cloud-hosted browsers—are all open source and available under Apache 2.0 in our repo here (give us a ✨!).
Thanks for reading!
Kernel provides browsers-as-a-service for web automations, agents, and more. Sign-up to get started here, join our Discord to chat with the community, and give our OSS repo a ⭐️ on Github.