


Introducing Browser Session Replays for Web Agents
An API to record cloud-based browser sessions as video replays. Fully open source under Apache 2.0

Today we’re launching browser session replays on Kernel: a new API that gives developers the ability to create video recordings of our cloud-hosted browsers. Replays help you see exactly what happened on your agent’s browser, whether you’re debugging browser automations, auditing web agent runs, or providing session playbacks to end users.
Get started: docs
See source: Github
Why we built browser replays
Kernel provides browsers-as-a-service for web agents and browser automations to connect to in the cloud. Browser automations and web agents are becoming popular to access and automate services that don’t have APIs, but there are many potential failure points when a browser automation fails. This gap is an issue for debugging, auditability, customer support, and agent trust. Video replays provide a way to visually trace what happened inside a browser session that a web agent drove.
Common tools in the ecosystem (like rrweb) try to reconstruct sessions by replaying DOM mutations. Those methods can be lossy and often miss key transitions, dynamic states, or renderings that happen outside of mutation events.
We wanted to provide something more reliable and opinionated: true video recordings of what the browser saw (WYSIW[hat]H[appened] semantics).
What you get
Our replays API provides the ability to generate video replays. It gives you controls for programmatically starting, stopping, and retrieving them.
Start a replay: Begin recording a browser session, with optional settings for framerate and max duration.
Stop a replay: Persist the recording and make the video available for review.
List replays: Retrieve all replays associated with a given browser session.
Download or stream a replay: Access the full video as a Kernel-hosted url or buffer, including in-progress streams with retry support.
Real world use case
Here’s what a typical replay-enabled flow might look like:
Launch a browser session with Kernel
Start a replay recording
Run your automation
Stop the replay
Perform sensitive actions (e.g. with PII) in live view — with no recording
Start a new replay if needed
Tear down the browser
You get precise control over what’s recorded and confidence that what you see is exactly what happened.
Under the hood
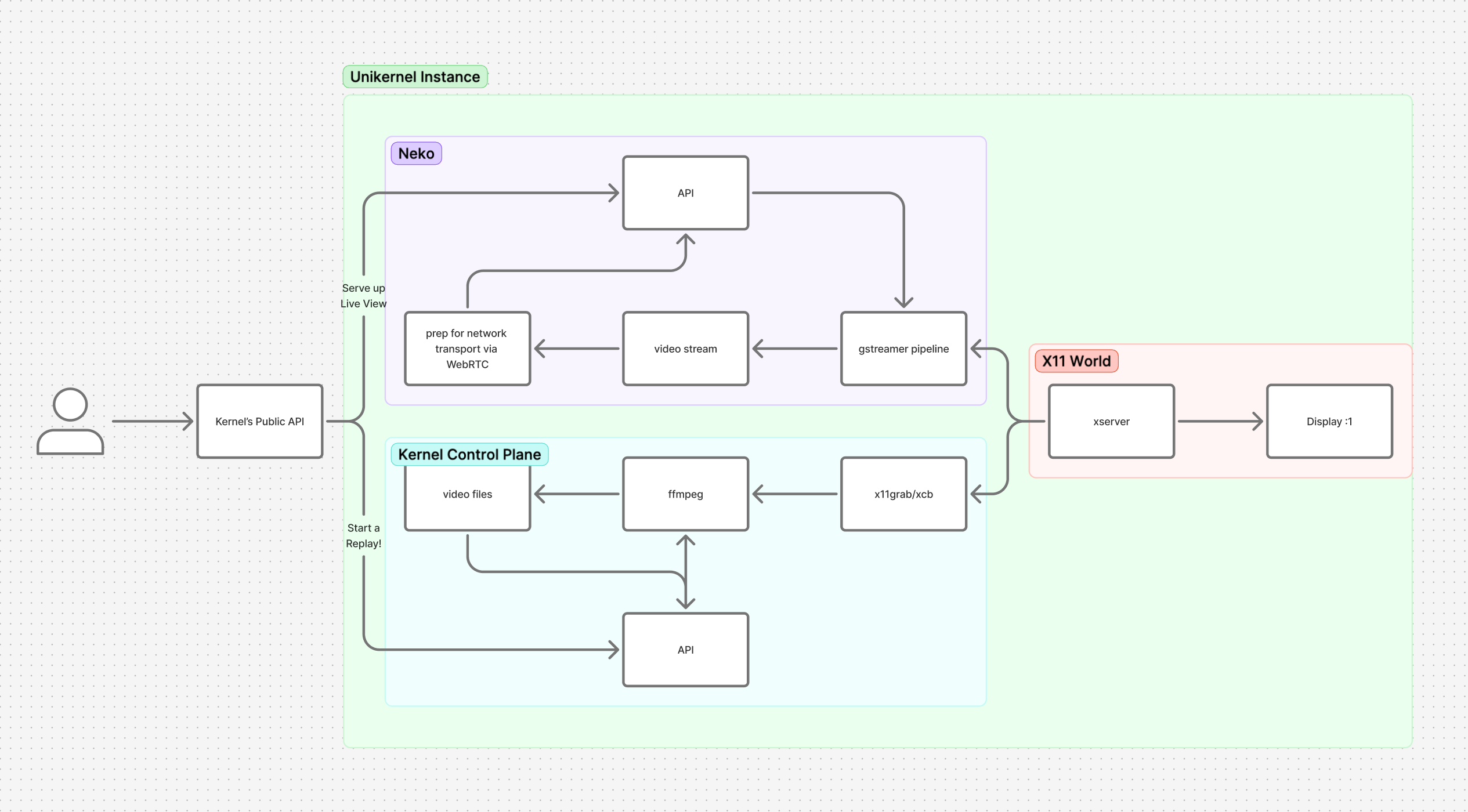
Based off our open source Chromium images, Kernel runs browsers inside lightweight, isolated unikernels orchestrated by our API. To support video replays:
We embedded a new API server inside every unikernel. This API exposes CRUD operations for controlling recordings (start, stop, list, delete)
When a user issues a replay command to Kernel’s user facing API, it’s delegated to the target unikernel, which manages the screen capture process.
The resulting recordings are streamed and persisted to encrypted cloud storage.
On browser teardown, we block on pulling any recordings that haven’t been saved already.
Challenges along the way
We had two core goals: keep the replay system flexible and avoid introducing heavyweight service dependencies. Building reliable video capture into cloud browsers without hardware acceleration turned out to be…non-trivial. Here are a few things we ran into!
Scale-to-zero and video encoding don’t mix
Unikraft, the technology that powers our cloud-based browsers, supports scaling to zero when idle — a great feature for resource efficiency. We hoped we could keep that behavior and still run replays by pausing and resuming around the recording lifecycle.
That didn’t work. Tools like ffmpeg weren’t designed to handle these operational modes gracefully, and it didn’t make sense for us to patch around its internals. We took a simpler path: any unikernel running a replay stays “hot” for the duration of the recording. Once the replay ends, scale-to-zero behavior resumes.
Live view and replays are separate systems
We forked neko to provide a live view of our browsers (under the hood, neko uses WebRTC and gstreamer), and we use ffmpeg to record videos for our replays. Both these components pull from the same underlying x11 display. This separation keeps the components simpler and easier to reason about, but it also creates edge cases.
For example, if either system changes the display resolution, it can cause the other to crash or corrupt the output. We ran into this a few times while testing dynamic resizing. Rather than coordinate resolutions across both pipelines, we chose to lock the display size while replays are running.
No GPUs = real trade-offs
Running Chromium, live view, and replays at the same time consumes a lot of CPU. We experimented with 1080p headful browser instances but it didn’t hold up well: our browsers slowed down, encoder performance dropped, and system load spiked. What resulted was unusable live view and replays with dropped frames. For the time being, we chose to fix resolution and cap the frame rate on Kernel’s browsers, generally keeping performance more stable and predictable. We’ll continue to optimize this with the goal of supporting custom resolution over time.
Thanks for reading!
Kernel provides browsers-as-a-service for web automations, agents, and more. Sign-up to get started here, join our Discord to chat with the community, and give our OSS repo a ⭐️ on Github.